NLP Series #1b: Transformers Assemble!
![]() (Above: A reference to the iconic Transformer robots, image courtesy [1])
(Above: A reference to the iconic Transformer robots, image courtesy [1])
Continuing off my [previous post], we’re now going to delve into three architectures/papers that, using the Transformer architecture [2], significantly changed the language modelling landscape of today (and have also made the news!) - GPT[3], GPT-2[4] and BERT[5].
What is language modelling?
Both GPT and BERT were designed with the same core idea in mind, transfer learning - NLP models like RNNs and Transformers can take ages to train (the large Transformer model took ~3.5 days on 8 P100 GPUs), so training a new network for each task can take nightmarishly long! Instead, we’d like to be able to take some kind of base, language model that understands how to embed different tokens using the context of the sentence/sequence they are in, and fine-tune those (along with some extra layers, as necessary) for different NLP tasks.
The language modelling objective is (for most variants) as follows: given an unsupervised corpus of tokens \(U = \{u_{1}, ..., u_{n}\}\), we want a language model that maximizes the following likelihood:
\[L_{1}(U) = \sum_{i} \log P(u_{i} | u_{i-k}, ..., u_{i-1}; \Theta)\]Where \(k\), in this case, is the size of the context window (the number of context tokens (either before or after) the model uses to predict the next token), and \(\Theta\) represents the parameters of our neural network we use to model the conditional probability \(P\).
The idea of using neural networks for language models is hardly new, however; as early as 2003, Prof. Yoshua Bengio et al had already started experimenting with A Neural Probabilistic Language Model [6] at the University of Montreal. Their model learned a feature vector for each word and expressed the conditional probability as a neural network on the corresponding vectors in an input (as shown in Figure 1 below:)
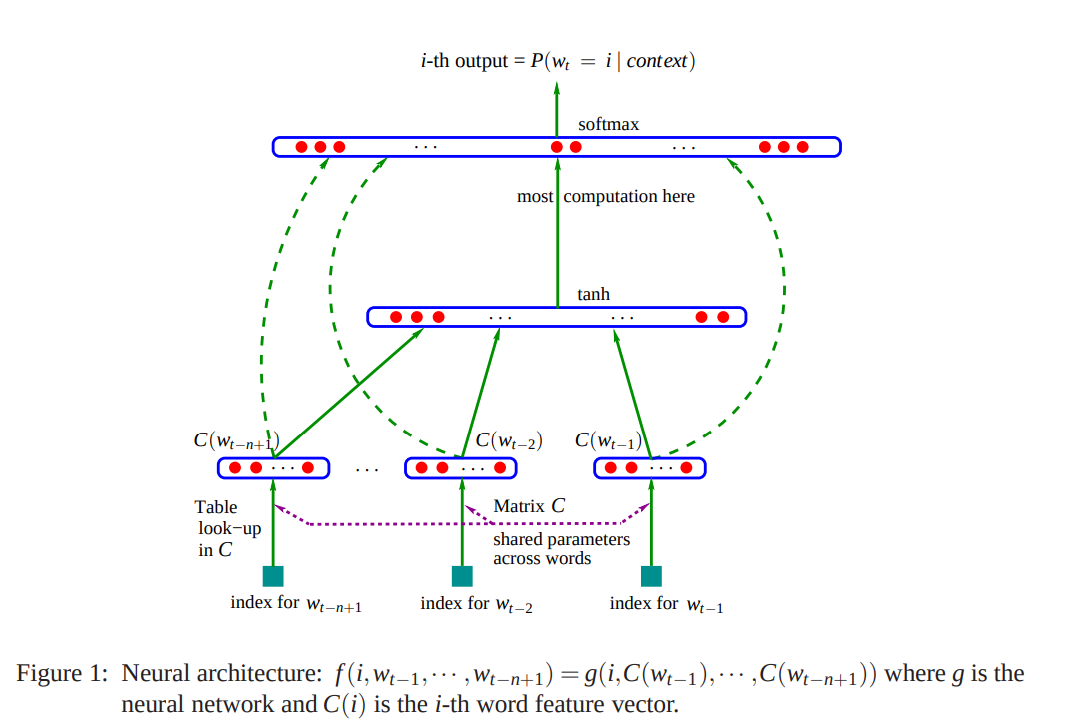
By 2018, when GPT came out, most language models used some kind of LSTM as the backbone for their probability estimator, such as Howard et al (who came up with a transfer-learning oriented LSTM-LM in [7]).
Howerver, both GPT and BERT recognized that parts of the Transformer setup could be leveraged to train:
-
Larger and much more powerful models (via the parallelism inherently built into the Transformer)
-
Using much larger corpuses, which would make transferring an easier task given the larger exposure the base model had gotten
GPT: The power of generative pre-training
GPT[3], by Radford et al, came out of OpenAI in 2018, and explored the power of using Transformers for unsupervised pre-training, followed by task-specific fine-tuning.
From my previous post, you might recall that the Transformer was trained with labelled translations (from English to German or French). While there are certainly large, labelled datasets for different NLP tasks,their size pales in comparison to the sheer amount of unlabelled, raw text data we have!
Language models are best suited to leverage this unlabelled data; since all a language model needs to do is predict the next token given a context window, you can train it on virtually any textual data, processing \(k\) tokens at a time and evaluating the log likelihood of the chosen token in the text, without further labelling required!
Radford et al, therefore, decided to modify the Transformer to make it more amenable for language modelling, as shown in Figure 2 below:
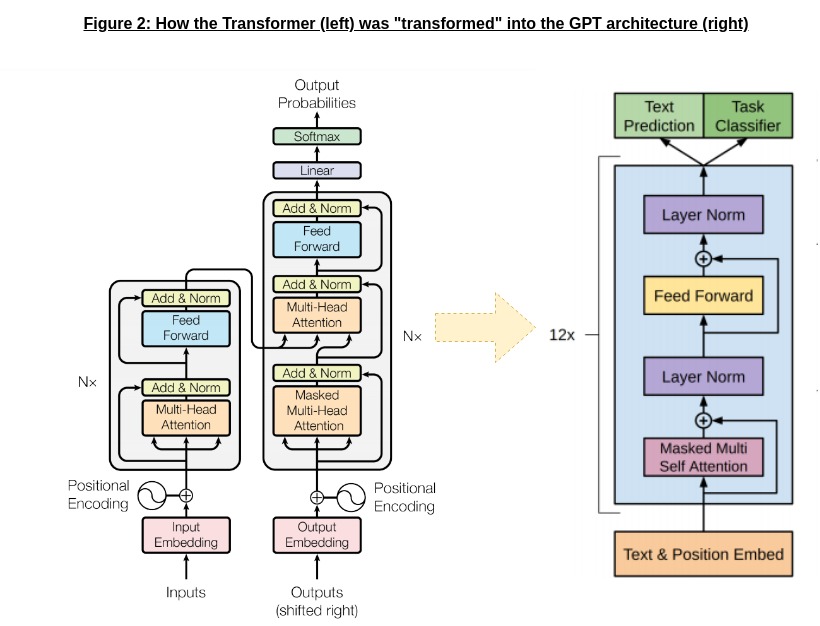
The GPT architecture is almost identical to the decoder of the Transformer - the only major difference is the elimination of the encoder-decoder attention layer (which makes sense, since GPT only has a decoder). As was the case in the original Transformer, the GPT decoder predicts probabilities for the next token, but the input is now the context window of previous tokens (instead of an ongoing translation to a target language).
A key point to note here is the use of the Masked Multi-Head Attention layer, which performs a very similar function in GPT to its role in the original Transformer decoder. In both cases, the masking helps preserve direction; GPT is a left-to-right language model, because the context window for a token only consists of previous tokens. While this might seem a bit trivial right now, it will become much more important when we discuss BERT.
In terms of the output, GPT differs a bit from the Transformer - as you can see in Figure 2, the output of the GPT network is piped to two different “tasks” - text prediction (a.k.a language modelling) and “Task Classifier”. The USP of the GPT network is that, after pre-training on language modelling, it fine-tunes its parameters for the specific NLP task in mind using the supervised data for that particular task, and “Task Classifier” represents the fine-tuning task. Interestingly though, even when fine-tuning GPT maintains language modelling as an auxillary task, which the authors argue helps the supervised model generalize well while also accelerating convergence!
However, not every task fits directly into the input structure for a Transformer decoder, because while GPT is trained on a contiguous and (relatively) unstructured stream of text from a corpus, many tasks (such as classification, Q&A, etc) involve structured sets of inputs. What the GPT work did, therefore, was to use a set of clever tricks to “transform” (pun, yet again, intended!) the input to each task into the GPT framework, as shown below in Figure 3:
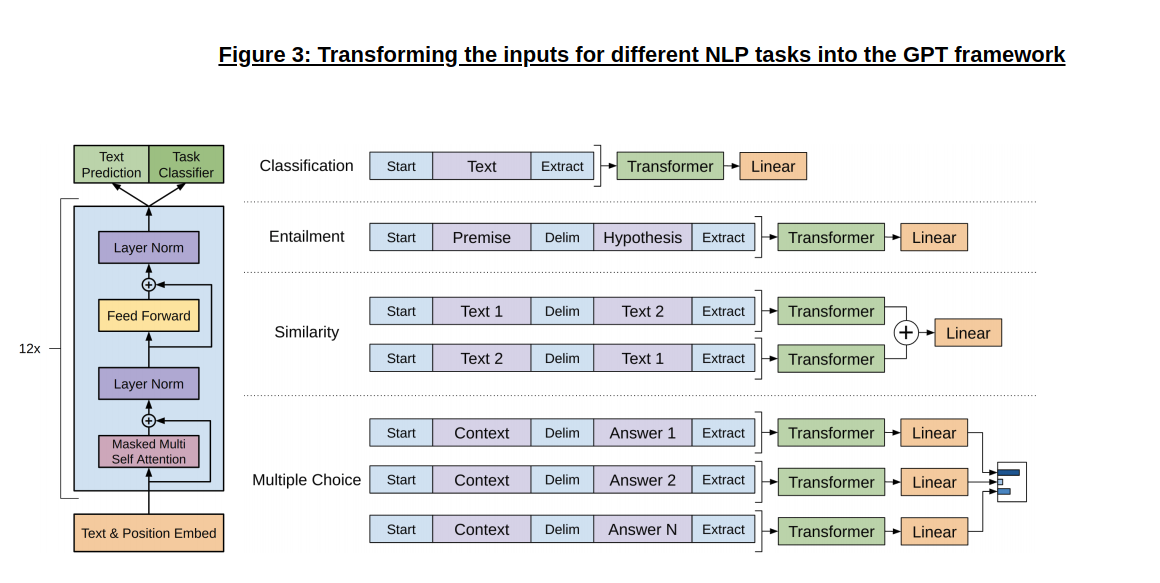
While classification is fairly straightforward, let’s take a quick look into some of other the target tasks and the corresponding transformations required:
- Textual entailment:
-
Task: Given a premise and a hypotheses, the task is to predict whether the facts in the premise imply the hypotheses. For example, given the following:
-
Premise: “An interplanetary spacecraft is in orbit around a gas giant’s icy moon”,
-
Hypotheses: “The spacecraft has the ability to travel between planets”,
You would expect the model to predict high entailment. If you’re interested in seeing how current models do on tasks like these, AllenNLP has a great demo!
-
-
Transformation: To make the input contiguous (instead of two separate pieces of text), the authors simply inserted a delimiting character between the premise and the hypotheses, and feed the output of GPT into a set of linear layers to predict the probabilities of entailment vs contradiction (or neutral).
-
- Similarity:
-
Task: As the name suggests, the task here is to predict how similar two given sentences/pieces of text are.
-
Transformation: Since the task for similarity has no implied order between the texts (unlike entailment), the authors feed both orders into the GPT, add the output sequences elementwise, and feed the result into a set of linear layers to predict the similarity score.
-
-
Multiple Choice: Q&A :
-
Task: For this task, we’re given three things: a context document \(z\), a question \(q\), and a set of possible answers \(a_{k}\) we want to predict an output distribution over.
-
Transformation: In similar fashion to the similarity task, the authors create \(k\) inputs of the form \([z; q; $; a_i]\) ($ is the delimiter); they feed each input in independently and softmax over each corresponding output to get the answer distribution.
-
While we will go into the results in more detail at the end of this post, for now it suffices to say that GPT outperformed every other baseline out there for virtually all the tasks we saw above, across different datasets for each task.
What was even more remarkable about GPT, however, was that it could do well even on tasks it had not been fine-tuned on. For instance, on SST2 (a sentiment analysis task), zero-shot GPT outscored other baselines, including a GPT model fine-tuned on SST2!
GPT showed us that developing a good, Transformer-based language model was sufficient to get state-of-the-art performance on many other related tasks, and went a significant way to alleviating the core problem of expensive transfer learning every time a new task came up.
GPT-2: The model so powerful it’s scary!

While GPT was powerful, GPT-2 was even more so; released a year later by Radford et al (the same group that worked on GPT at OpenAI), GPT-2 outperformed GPT and several other language models, while also showing strong performance on other tasks with no fine-tuning (a.k.a zero-shot learning).
Importantly, GPT-2 also showed the ability to generate much longer spans of text than previously thought possible - check out this short clip of a “news story” GPT-2 generated from a human-written prompt:
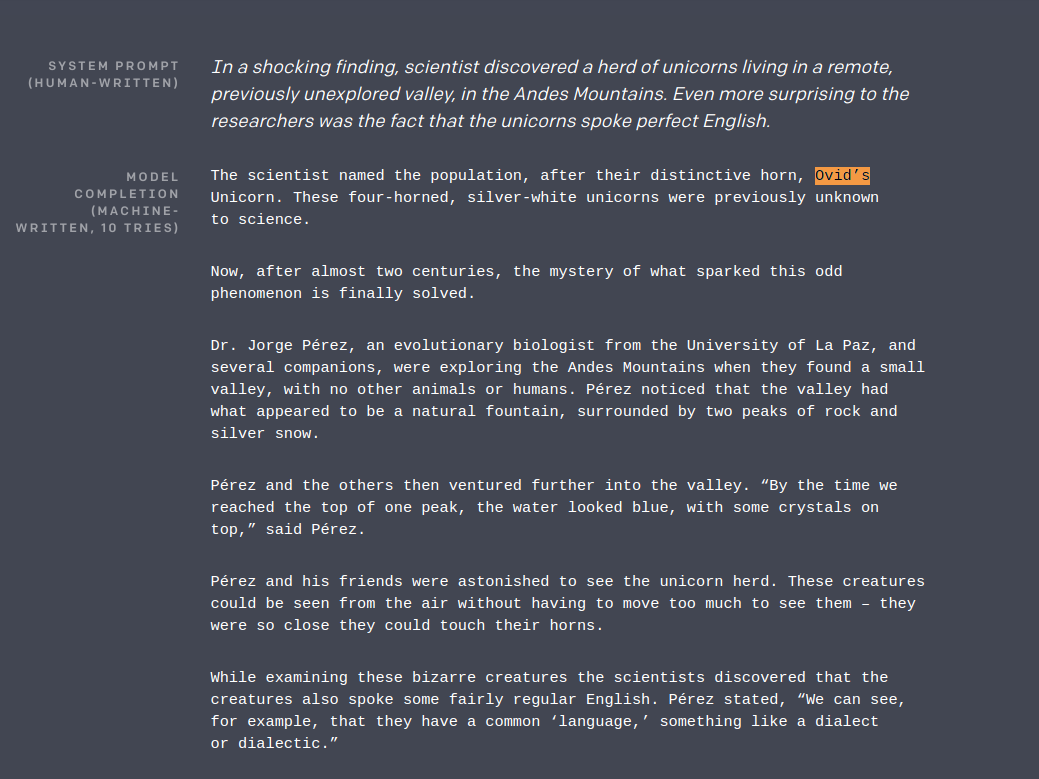
Its ability to generate such stories, given a simple human-written prompt, raised immediate ethical concerns around its potential use for things like “fake news”, which is likely what prompted OpenAI not to release the full model [9].
What’s even more surprising about GPT-2, however, is the fact that from an architectural/design perspective it is virtually identical to GPT! How, then, is it much better than the original model? The answer lies in the data it was trained on; GPT was trained on the BooksCorpus dataset [10], which while extensive in size was also limited by the kind of language used in books (as opposed to other forms of writing and speech).
To improve its performance for GPT-2, OpenAI therefore developed a new, gigantic dataset called WebText, with over 40GB of textual data scraped using outbound links in Reddit posts with 3 or more karma. Scraping the internet for large textual datasets had been tried before, such as with the Common Crawl dataset [11], but this often suffered from data quality issues; in contrast,the use of Reddit karma in WebText helped curate the quality of the webpages scraped by limiting it to links users thought were “useful, funny or informative”.
GPT-2, while still fairly recent as a paper, serves to remind us that data quality is just as important (if not more) than good model design; by simply augmenting the quality and quantity of data, OpenAI was able to train a much better model, on a much larger scale (the largest GPT-2 model has 1.2 billion parameters, a new high for neural networks even in the NLP domain!).
I’ll end this section by noting that AllenAI has a website where you can actually play around with the public version of the GPT-2 model, so have fun reading some generated sentences!
BERT: Bidirectionality + Transformers
As we discussed with the GPT series, the choice of using the Transformer decoder was very intentional; GPT is a left-to-right language model, using context windows on the left to predict tokens on the right. But is that the only way of modelling language?
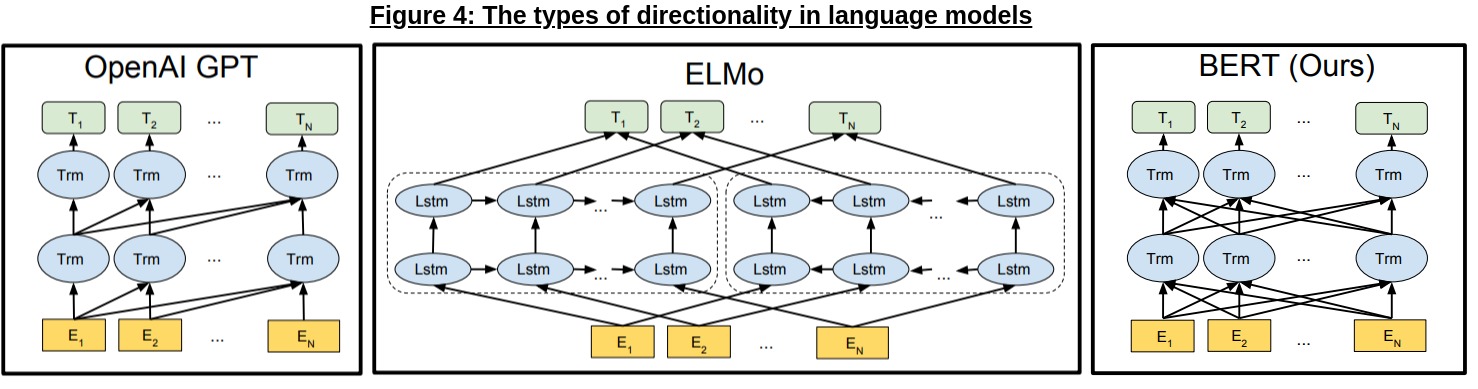
From Figure 4, we can see three types of directionality in GPT, ELMo [12] (another LSTM-based LM that generates contextualized word embeddings) and BERT.
GPT, as we’ve discussed, is unidirectional (only considering the leftwards context); ELMo, on the other hand, is somewhat bidirectional - it uses two separate LSTMs to represent left-to-right and right-to-left language models respectively, and concatenates the outputs of both to generate the final encoding per token.
But BERT, as we can see, is truly bidirectional - both directions are processed simultatenously, made possible by the fact that BERT uses the Transformer encoder as its building block (shown below in Figure 5a).
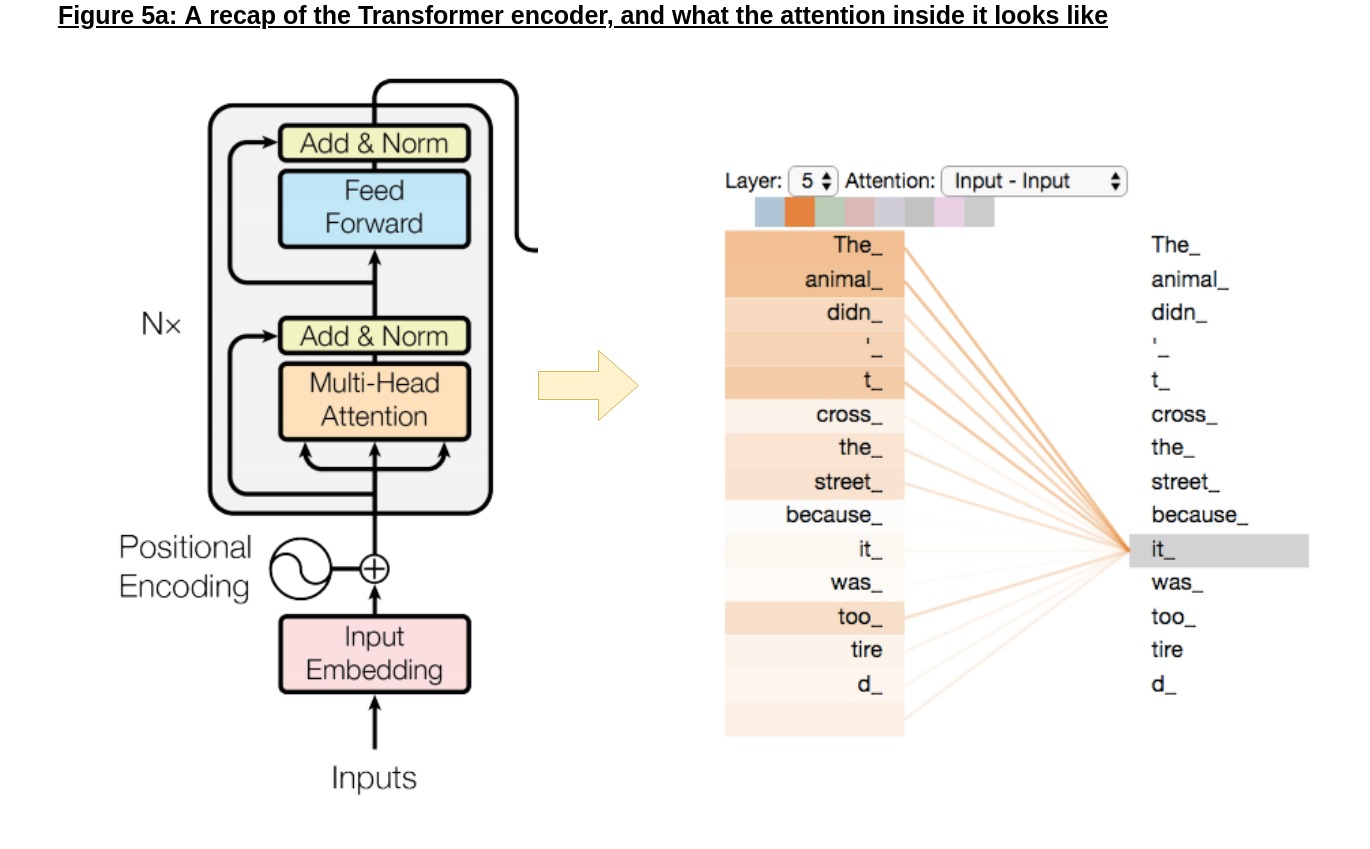
We’ve seen this before, but the important takeaway here is that the encoder, unlike the decoder (and therefore GPT), uses bidirectional attention; in the example shown, the attention mechanism looks across the sentence while encoding the token “it”.
BERT leverages this bidirectional attention mechanism in the encoder to build and train its language model, as we can see below in Figure 5b:
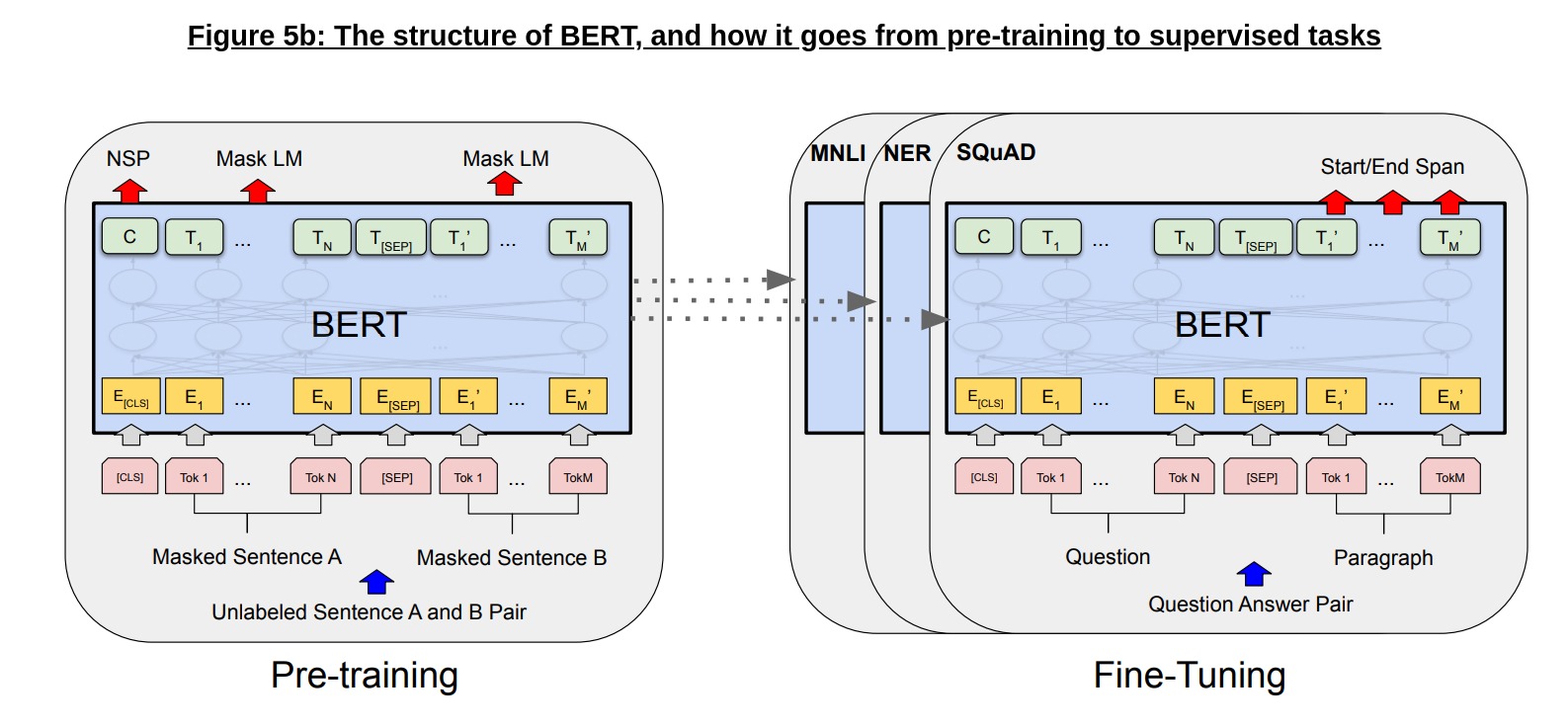
The input to BERT is slightly different from the standard Transformer encoder; in order to better model a range of NLP tasks, the BERT input is a pair of sentences, while the output is passed to two tasks - NSP (Next Sentence Prediction) and Masked LM (Language Modelling).
-
Masked LM: While bidirectionality is great as a feature, it does come with its own problems; naively, the encoder at each step can attend to every token in a sentence, including the current token. This is not a problem in the original Transformer, as the encoder simply encodes a source language sentence for the decoder to translate - however, in the language modelling objective, this would imply the context window for a token includes its own self!
To avoid this problem, Devlin et al used the Masked LM problem to train BERT instead; also known as the Cloze task, this involves masking out a set of tokens (at random) in the input to BERT, which it then must predict. Note that since the [MASK] token does not appear in real-world/fine-tuning inputs, the authors do not always use the [MASK] token as a replacement - they will also occasionally use another random token or even the actual token instead, but still train BERT to predict the “missing/changed” token.
-
NSP: While the LM (or Masked LM, in this case) objective can capture a significant amount of information needed for upstream tasks, many NLP tasks also require understanding how two sentences relate (such as Q&A or entailment). In order to better pre-train a model to be used on such tasks, BERT also uses the NSP (Next Sentence Prediction) task during the unsupervised phase.
The NSP task is a fairly straightforward classification task; given two sentences A and B, the model is tasked with predicting whether B is truly the sentence that follows A or just a random sentence (during training, they feed a mix of true and random sentence pairs). Note that this task is also unsupervised, and requires no further annotation or labelling apart from breaking the corpus into sentences.
Using this framework, BERT follows the same principles as GPT - pre-train with a large, unsupervised corpus (in this case, a mix of the BooksCorpus and English Wikipedia), and fine-tune the entire network for a specific task.
We will touch on this again in the results section (as was also promised with GPT!), but as with GPT, BERT yet again redefined the state-of-the-art on a set of tasks in the GLUE NLP benchmark [13]. Tasks ranged from sentiment analysis (SST-2) to SQUAD (Q&A), and BERT handily beat many LSTM-based models and GPT on almost all of them! (GPT-2 was more focused on long-term dependency and text generation, but it would be interesting to compare it directly to BERT.)
Impact
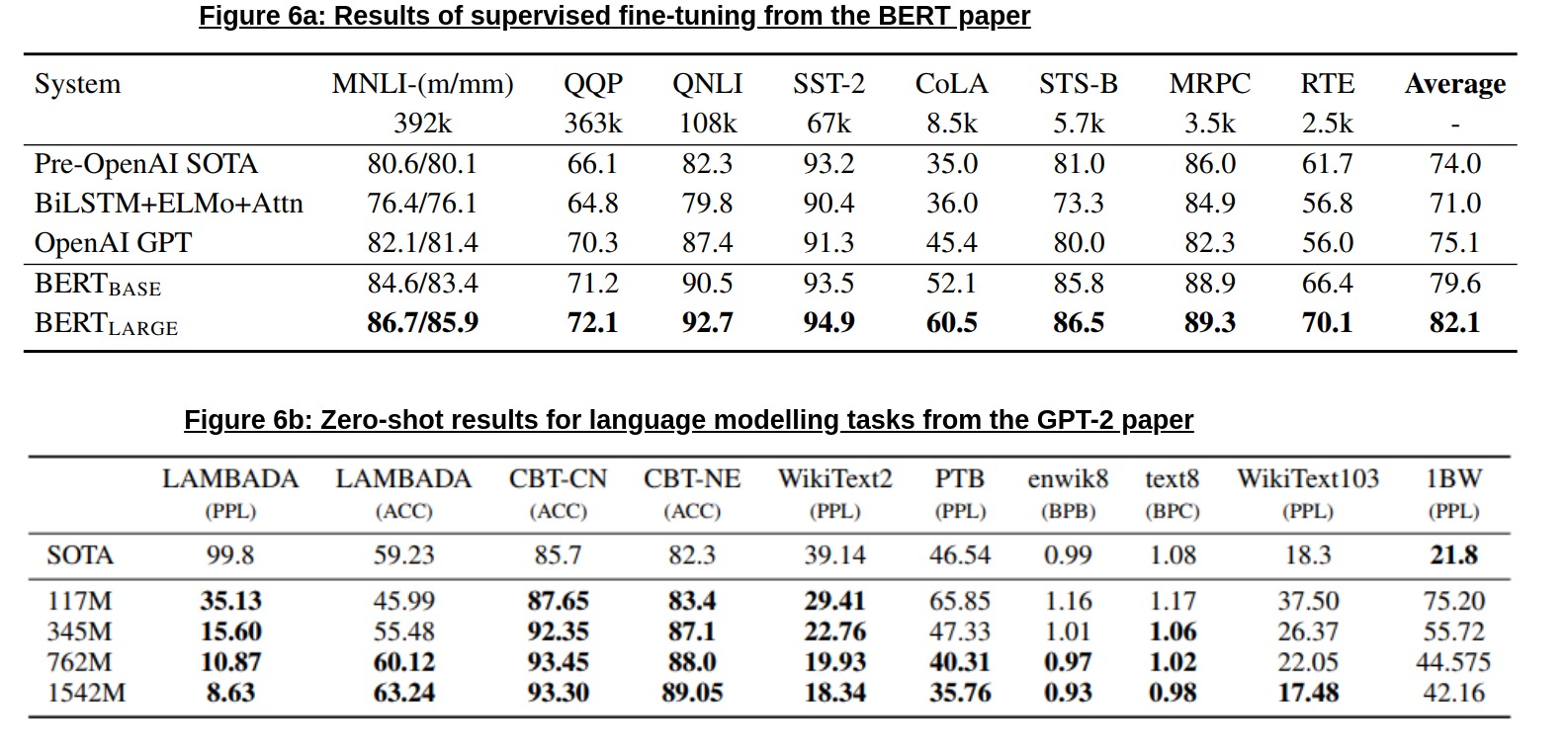
The results from GPT, GPT-2 and BERT are simply amazing; while GPT, and then BERT both became SOTA state-of-the-art for a variety of supervised NLP tasks overnight, GPT-2 has taken both model size and text generation to a level never seen before (and was deemed “too dangerous to release!”). I’ve included some of the numbers from the papers in Figures 6a and 6b at the below (especially for those of you who might want to compare to other, pre-existing models), which showcase just how big of a jump these models have been compared to the previous SOTA.
Going forward, these papers have sparked a flurry of further research into bigger, larger and better Transformer-based architectures. We’ve already seen Transformer-XL[14] and XLNet[15] surpass these in the past few months, NVIDIA Research has now trained an 8.3 billion parameter GPT-2 model [16], and it’s evident that Transformers and attention are the new paradigm of NLP research!
At the same time, however, it’s also important to remain cautious with these models; as OpenAI has warned us repeatedly, language models are as useful in the hands of malicious actors as they are for ML enthusiasts like you and me. Synthetic articles generated by GPT-2 are almost as credible as real New York Times articles for readers [17], and with the models only getting bigger and better, it is equally important to start thinking about some of the ethical concerns with our research.
Citations
- [1] Lego Transformers: MiniLEGOYoutuber, Pixabay
- [2] Attention is all you need: Vaswani et al, 2017
- [3] Improving Language Understanding by Generative Pre-Training: Radford et al, 2018
- [4] Language Models are Unsupervised Multitask Learners: Radford et al, 2019
- [5] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding: Devlin et al, 2019
- [6] Distributed Representations of Words and Phrases and their Compositionality: Mikolov et al, 2013
- [7] Universal Language Model Fine-tuning for Text Classification: Howard et al, 2018
- [8] Frieza’s Final Form: quickmeme.com
- [9] Better Language Models: Radford et al, OpenAI, 2019
- [10] Aligning books and movies: Towards story-like visual explanations by watching movies and reading books: Zhu et al, 2015
- [11] A Simple Method for Commonsense Reasoning: Trinh et Le, 2018
- [12] Deep contextualized word representations: Peters et al, 2018
- [13] GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
- [14] Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context: Dai et al, 2019
- [15] XLNet: Generalized Autoregressive Pretraining for Language Understanding: Yang et al, 2019
- [16] MegatronLM: Training Billion+ Parameter Language Models Using GPU Model Parallelism: NVIDIA ADLR, 2019
- [17] GPT-2: 6-Month Follow-Up: Jack Clark, Miles Brundage and Irene Solaiman, OpenAI, 2019
![[8]](https://impossiblehq.com/wp-content/uploads/2013/04/Final-Form.jpg){kind=link}